
Dev at Work: Accidental caching and refactoring philosophy
The day started at the gym as always, cardio (mostly spinning), chest and abs. With my hair still wet I rushed to work, just in time for our daily standup. Mathias worked from home, and many colleagues have started their summer vacation.
[caption id=“attachment_36363” align=“alignleft” width=“350”]
Sometimes I wish the team was bigger, that I had more people to discuss things with. I don’t like working in a vacuum. In particular when I need to make significant changes to the code base. The story I’m working on today is an interesting one.
Here is the backstory
A year ago, we came to the point where we realized that the only way we could improve performance was by implementing a cache. Values that were accessed often from our datastore, but didn’t change as often, and that also relied on heavier queries, could be cached instead.
Unfortunately, although I protested, we decided to implement our own cache. Caching is one of the harder thing in programming, and bugs that involve the cache are often difficult to figure out. The cache we implemented is not distributed, there is one per service, and it uses a memory cache object to hold cache entries where we allow any type of item to be cached- including complex objects.
The story I’m working on is called: Stop caching entity framework objects. Entity Framework (EF) is a complex ORM mapper, and we are using it ‘database first’. This means that EF looks at the database, and then auto-generates classes to match the tables, and the relations between them. Although the classes look like simple data transfer objects at first sight there is a lot that is happening in the background. The classes are wrapped with proxy classes that manage the relations to other classes (tables), there is built in change tracking, caching and a whole lot much more. The problems with caching EF contexts are many. Here are some:
Since the objects are tied to a context which is the dabasecontext you end up with several contexes. This means different problems, such as possibly working with a stale context without knowing.
Objects can be cached in different places. Say that I cache a Person with a list of Cards. And then I also have a different cache entry for just Cards. If I make changes to a card the person has I can easily end up with just updating the Cards cache item, but not the Person.Cards. We have inconsistent data- and this is really hard to detect. You often get obscure bugs.
The objects are of considerable size. EF objects are wrapped in DynamicProxy classes, have caching and change tracking etc. as mentioned before- and the objects are quite big.
If you dynamically open a connection, then you have to explicitly close it. Usually EF manages this for you, but not if you do this explicitly. So, the connection might not be returned to the connection pool, and you can leak connections. When a context object is disposed it would return the connections to the pool- BUT if we are caching the context, well- then its never disposed is it? Leaking connections is not fun- but I have a different post on that next week.
These are just some issues, there are many more. Please share your experience in the comments- and dear lord please let me know if I’m wrong in any of it- I really wish I had somebody to discuss this with.
Last week I found out that we were leaking connections- remember the timeouts I talked about? It’s a story I’m working on next week so I’ll get to that next week. As a part of the investigation I did some profiling with one of my favorite tools, RedGate ANTS memory profiler. I just wanted to see why we had so many connections sleeping and not being reused. And I noticed that we were caching EF objects. Crap.
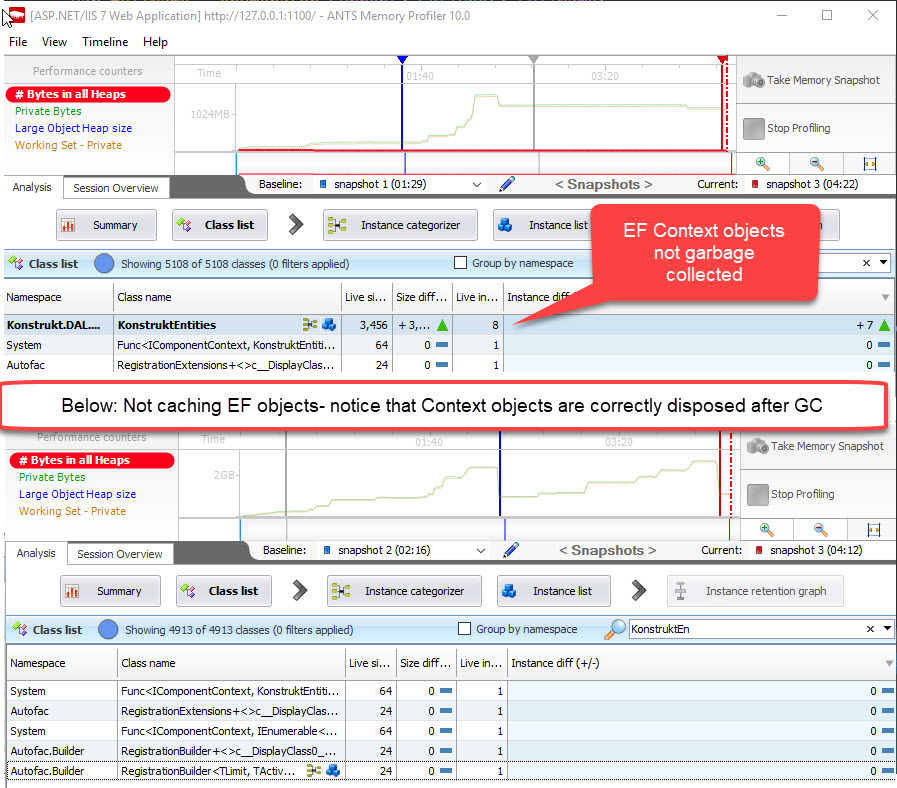
I ran the profiler again, but this time not caching items if they were EF objects. I logged the stacktrace if we tried to cache EF objects so I could find out where this happened.
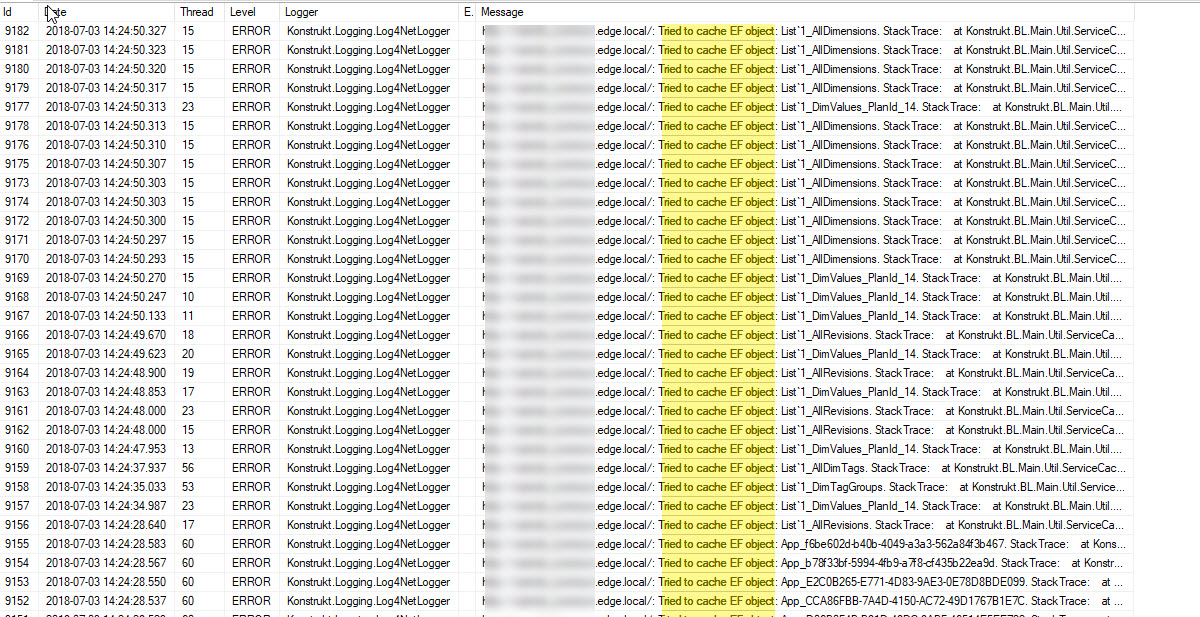
Half of our repositories (our data store access points) cached EF objects and thus also the context.
This is a problem and I have to fix it. But I’m not sure how. A whole lot more rewriting is needed to make this work, and I don’t know what the best solution is- or the most elegant solution. Although I would love to rewrite everything, we simply don’t have time for that right now as we have some urgent features to push out.
Let me explain how the legacy code looks like- and yes, its not pretty, but this is reality- and this is real code (that was there before I started, and will be around for a while after me).
We have a Dimension Controller in our API, and it has a GET method. It gets all the dimensions for a dataset such as a budget (it’s a finance system). It has an optional Boolean if the client wants to know if the dimension can be deleted or not (some dimensions cannot be deleted). The Controller which is in the API layer uses a DimensionService object from the BL (business layer) layer and calls the GetAll method. The method takes the same Boolean as earlier and calls the DimensionRepository in the DAL (data access layer) which checks if the dimensions exist in the cache, and if not caches them (as EF objects). The DimensionService then creates a different object, a ‘POCO’ object that differs from the EF objects as it has a nullable Boolean, IsDeletable. The property is set by doing a query to check some conditions.
Code (actual snippets):
DimensionController.cs (in API layer)
<span style="color: #3366ff;">
[HttpGet]
[Route("dimensions")]
public HttpResponseMessage Get(bool includeIsDeletable = false)
=> ToJson(_dimensionService.GetAll(includeIsDeletable));
</span> DimensionService.cs (in BL layer)
<span style="color: #3366ff;">
public IEnumerable<Shared.Poco.Dimension> GetAll(bool includeIsDeletable)
{
var pocos = _dimensionRepository.AllDimensions().Select(s => s.ToDimensionPoco()).ToList();
if (includeIsDeletable)
foreach (var dimension in pocos)
dimension.IsDeletable = !_dimensionRepository.UsedInPlan(dimension.DimensionId);</span>
<span style="color: #3366ff;">
return pocos;
}</span>
DimensionRepository.cs (in DAL layer)
<span style="color: #3366ff;">
public IList<Dimension> AllDimensions()
=> _serviceCacheHandler.GetOrAdd(Shared.Constants.<b>AllDimensionsCacheKey</b>, () => _context.Dimension.ToList());
</span> Alright. So How do I go about this?
First of all, let me just add that although we have discussed using code first instead of database first with EF- that is not something we can currently do. We have time pressure, bugs to fix and features to add- and changing EF model is not something we can make a priority. So I have to work around the constrains we have.
Anyway.
I want to cache a different object than the EF objects. I could create DomainEntities, objects that map one to one with the EF objects and cache a DomainEntity instead. I could use AutoMapper to manage the actual mapping, and skip tedious boilerplate code.
But, I need to decide if I will change the return type of the repository methods. Ideally, the repo wouldn’t return EF objects, for many reasons- but one would be that I would have to map back the cached object to a EF object before returning it- which just seems unnecessary. But changing the method return types means I would need to make the changes up the call tree, and that means rewriting a lot of code in many files, including our many tests and mocks. That’s alright, I’m not scared.
And for this specific example I would have to create a different, but similar object, that the service returns to the calling class (the controller) with that nasty IsDeletable property. I don’t like that the business layer is creating the view model object- but I’m assuming the dev that wrote that code wanted to keep the controllers slim.
I honestly don’t like the code at all, and I’m not saying I necessarily have a better solution- these are just my thoughts that I use to hopefully spark a discussion that yields a better solution.
At this point I haven’t decided what to do. What I WANT to do is rewrite the whole thing. But I always want to do that. At the same time I understand that 1. It might not end up as better code 2. This is a small story and not a big priority 3. I can’t do this on my own (this is just one out of maaaany examples, rewriting everything requires a lot of human resource and proper testing).
You don’t make big decisions on late Fridays, so on Monday I’ll figure this out. I packed my stuff, looked at some furniture with my SO, bought a watermelon and Chinese ramen and went home to watch the World Cup. And then, of course, sat down and wrote this :)

Comments
I enjoyed the story while I'm going back to home. From top of my head did you try store in cache using "AsNotracking" for the entities. More details here https://docs.microsoft.com/en-us/ef/core/querying/tracking#no-tracking-queries Enjoy the weekend and keep going with these great posts.
This is a great explanation of the real life decisions and compromises programmers have to make. If only we had time we could rewrite the application to work really well, instead we have to work out how we can fix the bug in code people have built over time, with minimal disruption. I came across this the other day when looking at Unit testing caching in a repository, it may help thinking about how you work round your problem - https://ardalis.com/introducing-the-cachedrepository-pattern .
Thank you! We actually use the cache repository pattern, but we are going to have to rethink that when we move to a cache where we won’t be caching complex objects as we will need to compose the objects ourselves. That is going to be fun!
Thank you Gabi! Was it you that wrote on Twitter about no tracking? It might solve a part o the problem, I’ll def look into that until we refactor the repos
The NoTracking unfortunately doesn’t remove the overhead and the problem with disposing the context :/ since we are working with a context per dependency (not per request) we are using unit of work pattern to attach the right objects to the right context- but it’s a good point that no tracking might be quite useful to avoid accidental updates on the wrong context. This is such a mess 😬😅
OMG. I think you've just solved my $work "connection leaking" problem that has been going on for years ;-D And indeed, it's been getting steadily better as we move more and more towards simpler Dapper repositories instead of relying on EF "magic" to pull in huge object graphs from the database.
It's a difficult problem for sure! In the short term I would at least consider revisiting the decision made a year ago to implement caching. Perhaps disabling the cache is an option if combined with better indexes at the database level. Adding more horsepower to the database server might also help.
Last modified on 2018-07-06